- 이전 포스트의 내용을 좀 더 자세하게 알아보자.
- Kafka의 토픽은 파티션의 그룹이고, 디스크에는 파티션 단위로 저장된다. 각 파티션마다 메시지(commit log)가 쌓이게 되는데, 이 메시지는 정렬되어 있고 불변성을 가진다. 또한 파티션의 모든 기록들을 Offset이라는 ID를 부여받는다.

- Kafka의 메시지는 Byte의 배열이며 String, JSON, Avro를 사용한다. Avro는 직렬화되어 성능을 높인 스키마를 표현하는 JSON이라고 생각하면 된다. 메시지의 크기에는 제한이 없지만 성능을 위해 작게(KB단위) 유지하는 것을 추천한다.
- 데이터는 사용자가 지정한 시간(Retention Period)만큼 저장한다. 또한 토익별로 지정도 가능하다. Consumer가 데이터를 받아가고 나서도 데이터는 저장되며, Retention Period가 지나면 데이터는 자동으로 삭제된다.
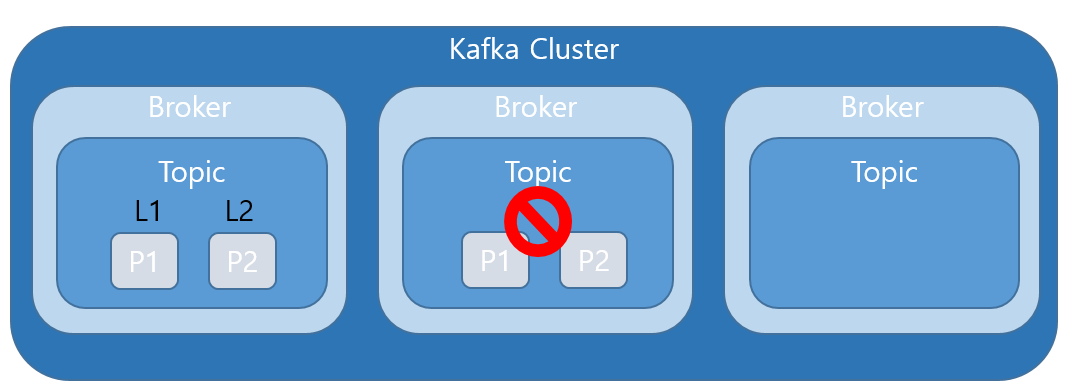
- Kafka 클러스터는 여러개의 브로커(서버)를 가질 수 있다. Kafka가 토픽을 생성하면 모든 브로커에 생성이되며, 파티션이 그림과 같이 여러 브로커에 걸쳐서 생성된다.

- Producer는 Kafka 토픽으로 메시지를 게시(post)하는 클라이언트 어플리케이션이다. 메시지를 어느 파티션에 넣을지 결정한다. 파티션 키(Key)를 지정할 경우 같은 키를 가진 메시지는 같은 파티션에 들어가며, 파티션 키를 지정하지 않은 경우 Round-Robin 방식으로 각 파티션에 메시지를 분배한다.
Round-Robin
라운드 로빈 스케줄링(Round Robin Scheduling, RR)은 시분할 시스템을 위해 설계된 선점형 스케줄링의 하나로서, 프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위(Time Quantum/Slice)로 CPU를 할당하는 방식의 CPU 스케줄링 알고리즘
- 아래 그림은 파티션 키가 존재할 경우의 그림이다. 같은 Key를 가진 메시지들은 같은 파티션에 보내진다.

- kafka 클러스터는 Relication Factor를 설정할 수 있는데, Replication Factor가 2일 경우 같은 파티션을 두 개까지 생성한다는 뜻이다. 만약 두번째 브로커가 죽었을 경우 Replication Factor로 인해 같은 파티션을 복제해 두었으므로 정상적인 작동이 가능하다. (일종의 안전 장치)
- 각 브로커는 복제된 파티션 중 대표를 하는 파티션 리더를 가지게 된다. 모든 R/W는 파티션 리더를 통해서 이루어지며, 다른 파티션들은 파티션 리더를 복제한다. 파티션 리더가 죽었을 경우, 다른 파티션 리더를 뽑는 식으로 작동한다.
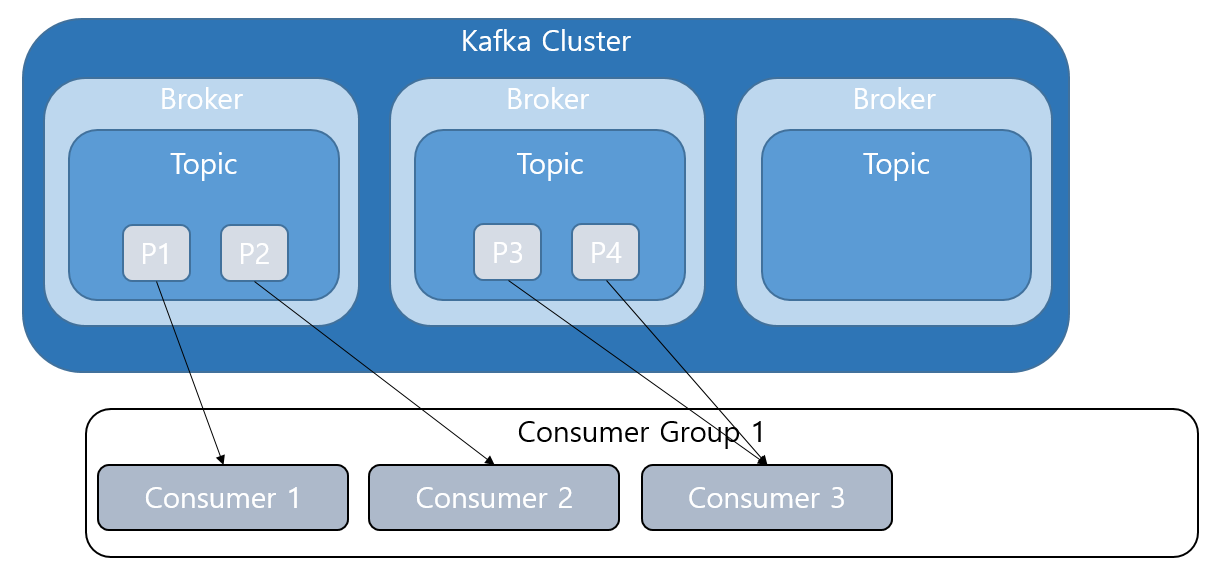
- Consumer는 메시지를 받는 역할을 하는 클라이언트 어플리케이션이다. 따로 Consumer Group을 지정하지 않으면 새 Consumer는 새로운 Consumer Group에 배정된다. 각 Comsumer Group은 모든 파티션으로부터 데이터를 받을 수 있지만, Consumer는 지정된 파티션으로부터만 데이터를 받을 수 있다. 예를 들어 아래그림과 같이 Consumer Group1은 P1, P2, P3, P4의 모든 파티션으로부터 데이터를 받을 수 있지만, Consumer1은 P2, P3만을 Consumer2는 P1, P4만을 받을 수 있다.

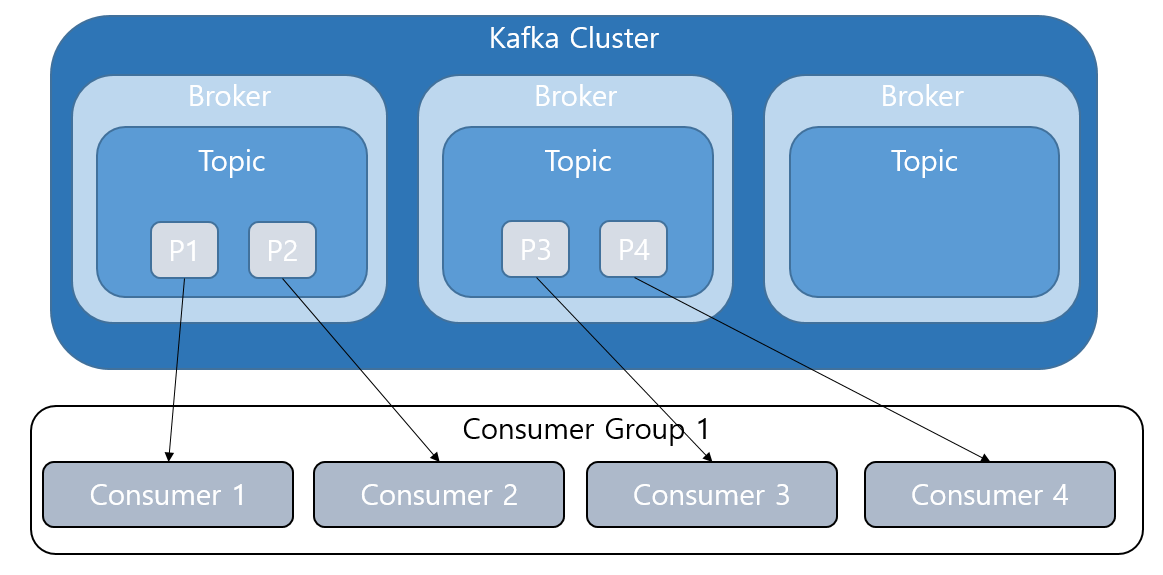
- Consumer가 제거되거나 추가될 때 Rebalacing이 이루어지는데 이는 Consumer가 최대한 균등한 데이터를 처리하도록 분배된다. 예를 들어 아래와 같은 상황에서 Consumer4가 추가된다면
- 아래와 같이 최대한 모든 Consumer가 균등하게 데이터를 처리하도록 리밸런싱된다.
- Kafka Zookeeper는 Consumer와의 통신, 메타데이터 저장, 카프카 상태관리 등의 기능을 한다. 분산 시스템간의 정보공유, 상태체크, 서버들 간의 동기화를 담당하며 Zookeeper역시 분산시스템의 일부이기 때문에 동작을 멈출 시 시스템에 영향을 줄 수 있다. 때문에 가용성을 위하여 Zookeeper도 클러스터로 구성되며, 클러스터는 홀수개로 구성되어 문제가 생겼을 경우 과반수가 가진 데이터 기준으로 데이터 일관성을 유지한다.
- Zookeeper의 Kafka 상태관리 기능은 Kafka 클러스터에 존재하는 브로커를 관리하고 모니터링하며, 토픽 리스트를 관리하고 토픽에 할당된 파티션과 Replication을 관리하며, 파티션의 리더가 될 부로커를 선택하고 리더가 다운될 경우 다음 리더를 선택하는 등의 역할을 수행하도록 도와준다. 또한 브로커들끼리 서로를 발견할 수 있도록 정보를 전달한다.
'Kafka' 카테고리의 다른 글
| Stream Processing With Kafka #5 (0) | 2023.05.07 |
|---|---|
| Stream Processing With Kafka #4 (0) | 2023.05.07 |
| Stream Processing With Kafka #3 (0) | 2023.05.07 |
| Stream Processing With Kafka #1 (0) | 2023.05.05 |