- 엘라스틱서치는 (1)루씬(Lucene) 기반의 오픈소스 검색 엔진이다. HTTP 기반의 REST API를 활용하여 요청 및 응답에 JSON을 활용해 다양한 플랫폼에서 개발이 가능하며, 정형화되지 않은 문서도 자동으로 색인하고 검색할 수 있다(Schemaless). 또한 (2)멀티테넌시가 가능하고 전문 검색 엔진을 제공한다. logstash 또는 fluentd로 로그를 변환하고 kibana를 연결하여 준실시간으로 로그를 분석하고 시각화 할 수 있다. NoSQL의 일종으로 분류할 수 있고, 기본적으로 검색엔진이지만 MongoDB 같은 대용량 스토리지로도 활용이 가능하다.
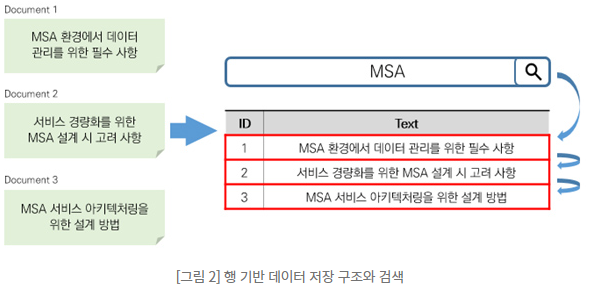
- (1) 아래 그림을 보면 RDB와 루씬 기반의 데이터 구조의 극명한 차이점을 볼 수 있다. RDB는 행을 기반으로, 엘라스틱서치는 단어를 기반으로 (역인덱스, Inverted Index) 데이터를 저장한다. 이로인해 RDB는 데이터의 수정 및 삭제에서의 장점이 있고 루씬 기반의 DB는 검색에 있어서 장점이 있다.

- (2)멀티테넌시(Multi-tenancy)란 소프트웨어 애플리케이션의 단일 인스턴스가 여러 고객에게 서비스를 제공하는 아키텍처다. 웹메일 서비스가 대표적인 멀티테넌시 아키텍처 소프트웨어 이다. 만약 웹메일에 접속했는데 모든 사용자의 메일이 하나의 메일함에서 보인다면 아무도 사용하지 않을 것이다. 멀티테넌트 아키텍처 덕분에 사용자 별로 데이터 설정 및 화면 구성등을 개인화할 수 있게 되었고, 이 기술이 발전해감에 따라 클라우드도 본격 확산되었다고 할 수 있다.
- 그렇다면 엘라스틱서치는 왜 멀티테넌시 구조라고 할 수 있을까? 엘라스틱서치는 여러개의 분리된 인덱스(indices)를 그룹으로 저장한다. 엘라스틱서치에서는 서로 다른 인덱스일지라도 검색할 필드명만 같으면 하나의 쿼리로 묶어서 검색하고 한번에 조회가 가능하다. 이 때문에 멀티테넌시 구조를 따른다고 볼 수 있다.
- 이러한 장점에도 불구하고 단점도 명확하다.
1. 완전 실시간은 아니다. 색인된 데이터는 1초 정도 뒤에나 검색이 가능하다. 그 이유는 내부적으로 commit과 flush 등의 복잡한 과정을 거치기 때문이다.
2. Transaction Rollback을 지원하지 않는다. 롤백과 트랜잭션은 비용소모가 크기 때문에 클러스터의 성능 향상을 위함이다.
3. 데이터의 Update를 제공하지 않는다. 업데이트 명령이 올 경우 기존 문서를 삭제하고 새로운 문서를 생성한다. 업데이트에 비해 많은 비용이 들지만 이를 통해 불변성(Immutable)을 취한다는 장점도 있다.
ref)
https://www.samsungsds.com/kr/insights/elastic_data_modeling.html
https://ko.wikipedia.org/wiki/%EC%9D%BC%EB%9E%98%EC%8A%A4%ED%8B%B1%EC%84%9C%EC%B9%98
'Elasticsearch' 카테고리의 다른 글
| Elasticsearch 정리 #2 (데이터 색인과 텍스트 분석) (0) | 2022.11.30 |
|---|---|
| Elasticsearch Query 모음 (0) | 2022.11.15 |