- 앞에서 도커에 대한 간략한 정리를 했으니 쿠버네티스가 무엇인지 알아보자.
쿠버네티스(kubenetes, k8s)는 컨테이너화된 앱의 작업을 자동화하는 컨테이너 오케스트레이션 오픈소스 플랫폼이다.
컨테이너화된 애플리케이션을 배포하고 확장하는 데 수동 프로세스가 필요하지 않다. 즉, Linux 컨테이너를 실행하는 호스트 그룹을 함께 클러스터링할 수 있으며 쿠버네티스를 통해 이러한 클러스터를 쉽고 효율적으로 관리할 수 있다. 클러스터는 퍼블릭 클라우드, 프라이빗 클라우드 또는 하이브리드 클라우드 전체로 호스트를 확장할 수 있다. 이러한 이유로 쿠버네티스는 Apache Kafka를 통한 실시간 데이터 스트리밍과 같이 신속한 확장을 요하는 클라우드 네이티브 애플리케이션을 호스팅하는 데 이상적인 플랫폼이다.
- 쿠버네티스의 장점은 쿠버네티스를 통해 물리 또는 가상 머신의 클러스트에서 컨테이너를 예약하고 실행할 수 있는 플랫폼이 확보된다는 것이다. 또한 다음의 작업에 있어서 이점이 있다.
- 서비스 디스커버리와 로드 밸런싱 : 쿠버네티스는 DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있다. 컨테이너에 대한 트래픽이 많으면, 쿠버네티스는 네트워크 트래픽을 로드밸런싱하고 배포하여 배포가 안정적으로 이루어질 수 있다.
- 스토리지 오케스트레이션 : 쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 공급자 등과 같이 원하는 저장소 시스템을 자동으로 탑재 할 수 있다.
- 자동화된 롤아웃과 롤백 : 쿠버네티스를 사용하여 배포된 컨테이너의 원하는 상태를 서술할 수 있으며 현재 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있다. 예를 들어 쿠버네티스를 자동화해서 배포용 새 컨테이너를 만들고, 기존 컨테이너를 제거하고, 모든 리소스를 새 컨테이너에 적용할 수 있다.
- 자동화된 빈 패킹(bin packing) : 컨테이너화된 작업을 실행하는데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공한다. 각 컨테이너가 필요로 하는 CPU와 메모리(RAM)를 쿠버네티스에게 지시한다. 쿠버네티스는 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있도록 해준다.
- 자동화된 복구(self-healing) : 쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다.
- 시크릿과 구성 관리 : 쿠버네티스를 사용하면 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 저장하고 관리 할 수 있다. 컨테이너 이미지를 재구성하지 않고 스택 구성에 시크릿을 노출하지 않고도 시크릿 및 애플리케이션 구성을 배포 및 업데이트 할 수 있다.
- 쿠버네티스를 이해하기 위해서는 우선 클러스터의 구조를 이해해야 한다. 클러스터 전체를 관리하는 컨트롤러로써 마스터가 존재하고, 컨테이너가 배포되는 머신인 Node가 존재한다.

- 쿠버네티스는 크게 기본 오브젝트(Basic Object)와 기본 오브젝트를 관리하는 기능을 가진 컨트롤러(Controlloer)로 구성된다. 그리고 오브젝트 스펙(Spec) 이외에 추가정보인 메타(Meta) 데이터로 구성이 된다.
- 기본 오브젝트
- 기본 오브젝트는 쿠버네티스에서 컨테이너화되어 배포 및 관리되는 앱의 워크로드를 기술하는 오브젝트로 Pod, Service, Volume, Namespace 4가지가 있다.
- Pod: 쿠버네티스에서 가장 기본적인 단위로 컨테이너화 된 앱이다. 쿠버네티스에서는 컨테이너를 Pod 단위로 배포하는데 Pod는 하나 또는 그 이상의 컨테이너를 포함한다.
- 그렇다면 컨테이너를 개별적으로 배포하지 않고 왜 Pod 단위로 묶어서 배포할까? 그 이유는 다음과 같다.
1. Pod 내의 컨테이너는 IP와 Port를 공유한다.
ex) localhost 상에서 컨테이너 A의 포트가 1010 컨테이너 B는 2020일 때 A에서 B를 호출할 때 localhost:2020으로 호출할 수 있으며 역도 성립한다.
2. Pod 내의 컨테이너간의 디스크 볼륨을 공유할 수 있다.
ex) 로깅 서버 컨테이너 A와 로그 추출 및 변환 컨테이너 B가 있다고 하자. A에서 생성한 로그는 test라는 디렉토리에 저장되고 B에서 이 로그를 바탕으로 필요한 로그를 추출 및 변환하는 사이드카 패턴(Side car pattern)으로 배포된다고 생각하면 아래 그림과 같은 형태를 띈다.
- Volume: 컨테이너는 재시작되거나 배포될 때 마다 컨테이너 내의 디스크에 기록된 내용이 유실된다. DB역할을 하는 컨테이너가 필요할 때 이는 치명적일 수 있다. 때문에 파일을 영구적으로 저장하기 위한 스토리지가 필요한데 이를 볼륨(Volume)이라고 한다. 쉽게 말해서 볼륨은 컨테이너의 외장 디스크라고 생각하면 된다.
- Service: 일반적인 분산환경에서는 보통 여러개의 Pod를 서비스하면서 로드밸런서를 이용하여 하나의 IP와 포트로 묶어서 서비스를 제공한다. Pod의 경우에는 동적으로 생성이 되고, 장애가 생기면 자동으로 리스타트 되면서 그 IP가 바뀌기 때문에, 로드밸런서에서 Pod의 목록을 지정할 때는 IP주소를 이용하는 것은 어렵다. 또한 오토 스케일링으로 인하여 Pod 가 동적으로 추가 또는 삭제되기 때문에, 이렇게 추가/삭제된 Pod 목록을 로드밸런서가 유연하게 선택해 줘야 한다.
그래서 사용하는 것이 라벨(label)과 라벨 셀렉터(label selector) 라는 개념이다.
서비스를 정의할때, 어떤 Pod를 서비스로 묶을 것인지를 정의하는데, 이를 라벨 셀렉터라고 한다. 각 Pod를 생성할때 메타데이타 정보 부분에 라벨을 정의할 수 있다. 서비스는 라벨 셀렉터에서 특정 라벨을 가지고 있는 Pod만 선택하여 서비스에 묶게 된다. 아래 그림은 서비스가 라벨이 “myapp”인 서비스만 골라내서 서비스에 넣고, 그 Pod간에만 로드밸런싱을 통하여 외부로 서비스를 제공하는 형태이다.
- NameSpace : 클러스터내의 논리적인 분리단위이다. 패키지명 정도로 생각하면 편하다. Pod,Service 등은 네임 스페이스 별로 생성이나 관리가 될 수 있고, 사용자의 권한 역시 이 네임 스페이스 별로 나눠서 부여할 수 있다.
예를 들어 하나의 클러스터 내에, 개발/운영/테스트 환경이 있을때, 클러스터를 개발/운영/테스트 3개의 네임 스페이스로 나눠서 운영할 수 있다. 개발계에는 CPU 100, 운영계에는 CPU 400과 GPU 100개 식으로, 사용 가능한 리소스의 수를 지정할 수 있다.
cf) 주의할 점은 네임 스페이스는 논리적인 분리 단위이지 물리적이나 기타 장치를 통해서 환경을 분리(Isolation)한것이 아니다. 다른 네임 스페이스간의 pod 라도 통신은 가능하다. 물론 네트워크 정책을 이용하여, 네임 스페이스간의 통신을 막을 수 있지만 높은 수준의 분리 정책을 원하는 경우에는 쿠버네티스 클러스터 자체를 분리하는 것을 권장한다.
+ Label : 라벨은 쿠버네티스의 리소스를 선택하는데 사용이 된다. 라벨 검색 조건에 따라 특정 라벨을 가지는 리소스만을 선택하여 사용할 수 있다. 라벨은 metadata 섹션에 key/value 쌍으로 정의가 가능하며 하나의 리소스에는 하나 또는 그 이상의 라벨을 동시에 적용할 수 있디.
ex)
다음 예제는 my-service 라는 이름의 서비스를 정의한것으로 셀렉터에서 app: myapp 정의해서 Pod의 라벨 app이 myapp 것만 골라서 이 서비스에 바인딩해서 9376 포트로 서비스 하는 예제이다.
| kind: Service apiVersion: v1 metadata: name: my-service spec: selector: app: myapp ports: - protocol: TCP port: 80 targetPort: 9376 |
- 컨트롤러
- 컨트롤러는 기본 오브젝트를 생성하고 이를 관리해주는 역할을 해준다. ReplicationController(aka RC), ReplicationSet, DaemonSet, Job, StatefulSet, Deployment 들이 있다.
- ReplicationController : Pod를 지정된 숫자로 가동시키고 관리한다. 크게 3파트로 구성된다.
1. Selector : 라벨을 기반으로, RC가 관리한 Pod를 가지고오는데 사용한다.
2. Replica 수 : RC에 의해서 관리되는 Pod 수이다.
ex) replica가 3이면 3개의 Pod만 띄우도록 한다.
3. Template : Pod를 띄울 때 Pod가 Replica 수보다 적게 떠있다면 템플릿에서 정의된 Pod를 Replica 수에 맞추어 새로 띄운다.
ex)
- ReplicaSet : Replication Controller 의 새버전으로 생각하면 된다. 큰 차이는 없고 Replication Controller 는 Equality 기반 Selector를 이용하는데 반해, Replica Set은 Set 기반의 Selector를 이용한다.
- Deployment : Pod 배포를 위해서 RC를 생성하고 관리하는 역할을 하며, 특히 롤백을 위한 기존 버전의 RC 관리등 여러가지 기능을 포괄적으로 포함하고 있다. 사실상 가장 많이 쓰이는 컨트롤러이다.
- DaemonSet : Pod가 각각의 노드에서 하나씩만 돌게 하는 형태로 Pod를 관리하는 컨트롤러이다. 이러한 워크로드는 서버의 모니터링이나 로그 수집용으로 많이 사용된다. 아래의 그림을 보면 이해가 쉽다.
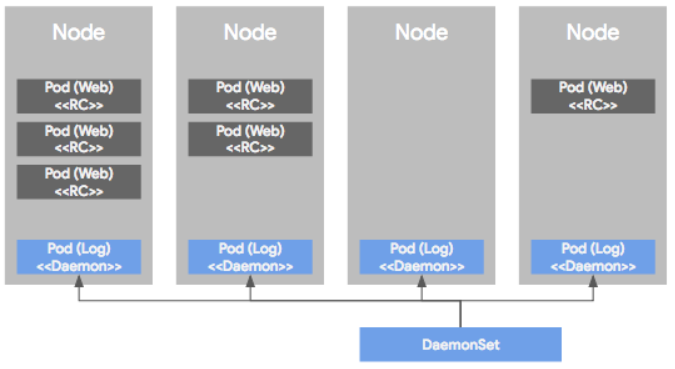
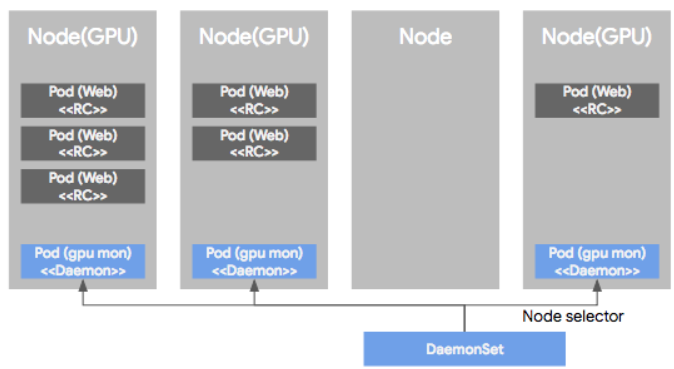
만약 특정 GPU를 사용하는 노드들의 로그만을 수집하고 싶다면 그 장비가 설치된 노드만을 모니터링하는 것도 가능하다.
- Job : 워크로드 모델중에서 배치나 한번 실행되고 끝나는 형태의 작업이 있을 수 있다. 예를 들어 원타임으로 파일 변환 작업을 하거나, 또는 주기적으로 ETL 배치 작업을 하는 경우에는 웹서버 처럼 계속 Pod가 떠 있을 필요없이 작업을 할 때만 Pod 를 띄우면 된다. 이러한 형태의 워크로드 모델을 지원하는 컨트롤러를 Job이라고 한다. Job에 의해서 관리되는 Pod는 Job이 종료되면, Pod 를 같이 종료한다.

job을 정의할때는 보통 아래와 같이 컨테이너 스펙 부분에 image 뿐만 아니라, 컨테이너에서 Job을 수행하기 위한 커맨드(command) 를 같이 입력한다.
| apiVersion: batch/v1 kind: Job metadata: name: pi spec: template: spec: containers: - name: pi image: perl command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] restartPolicy: Never backoffLimit: 4 |
만약 Job이 끝나기 전에 만약에 비정상적으로 종료된다면 어떻게 될까? 두 가지 방법으로 설정할 수 있는데, 장애시 다시 시작하게 하거나 또는 장애시 다시 시작하지 않게 할 수 있다. 다시 시작의 개념은 작업의 상태가 보장되는것이 아니라, 다시 처음부터 작업이 재 시작되는 것이기 때문에 resume이 아닌 restart의 개념임을 잘 알아야하고, 다시 시작 처음부터 작업을 시작하더라도 데이타가 겹치거나 문제가 없는 형태라야 한다.
- Cronjob : 주기적으로 정해진 스케줄에 따라 Job 컨트롤러에 의해 작업을 실행해주는 컨트롤러이다. 다른 점은 CronJob 스펙 설정 부분에 “schedule”이라는 항목이 있고 반복 조건을 unix cron과 같이 설정하면 된다.
| apiVersion: batch/v1beta1 kind: CronJob metadata: name: hello spec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: containers: - name: hello image: busybox args: - /bin/sh - -c - date; echo Hello from the Kubernetes cluster restartPolicy: OnFailure |
- StatefulSet : 데이터베이스와 같은 상태를 가지는 Pod를 관리하기 위한 컨트롤러이다.
- 볼륨
- 쿠버네티스의 볼륨에는 여려가지 종류가 있는데 크게 임시 디스크(emptyDir), 로컬디스크(hostPath), 네트워크 디스크 등이 있다.
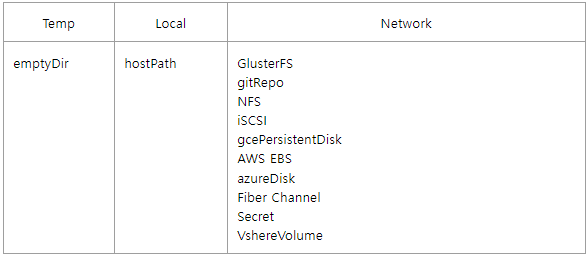
- empytDir : emptyDir은 Pod가 생성될때 생성되고, Pod가 삭제 될때 같이 삭제되는 임시 볼륨이다.
단, Pod 내의 컨테이너 크래쉬되어 삭제되거나 재시작 되더라도 emptyDir의 생명주기는 컨테이너 단위가 아니라, Pod 단위이기 때문에, emptyDir은 삭제 되지 않고 계속해서 사용이 가능하다.
- hostPath : hostPath는 노드의 로컬 디스크의 경로를 Pod에서 마운트해서 사용한다. 같은 hostPath에 있는 볼륨은 여러 Pod 사이에서 공유되어 사용된다. 또한 Pod가 삭제 되더라도 hostPath에 있는 파일들은 삭제되지 않고 다른 Pod가 같은 hostPath를 마운트하게 되면, 남아 있는 파일을 액세스할 수 있다.
- 아래는 노드의 /tmp 디렉토리를 hostPath를 이용하여 /data/shared 디렉토리에 마운트 하여 사용하는 예제이다.
apiVersion: v1
kind: Pod
metadata:
name: hostpath
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: terrypath
mountPath: /data/shared
volumes:
- name : terrypath
hostPath:
path: /tmp
type: Directory
- PV (Persistent Volume) & PVC(Persistent Volume Claim)
- 시스템 관리자가 실제 물리디스크를 생성한 후에, 이 디스크를 PersistentVolume이라는 이름으로 k8s에 등록한다.
개발자는 Pod를 생성할 때 볼륨을 정의하고, PVC를 지정하여 관리자가 생성한 PV와 연결한다. 즉, 시스템 관리자가 생성한 물리 디스크를 쿠버네티스 클러스터에 표현한것이 PV이고 Pod의 볼륨과 이 PV를 연결하는 관계가 PVC가 된다.
- 이때 주의할점은 볼륨은 생성된 후에 직접 삭제하지 않으면 삭제되지 않는다. PV의 생명 주기는 쿠버네티스 클러스터에 의해서 관리되며, Pod와 상관없이 직접 생성하고 삭제해야 한다.
- 정리하면 PV/PVC는 아래와 같은 과정을 거친다
1. 물리 디스크 생성 : 클라우드 콘솔에서 물리디스크를 생성한다. 디스크 이름을 pv-test-disk라고 가정하자.
2. PV선언 : 생성된 디스크로 PV를 선언한다. 아래는 PV yaml 파일생성 예제이다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-demo
spec:
storageClassName:
capacity:
storage: 20G
accessModes:
- ReadWriteOnce
gcePersistentDisk:
pdName: pv-test-disk
fsType: ext4
3. PVC 생성 : 앞에서 생성한 pv-demo를 사용하는 PVC yaml 파일을 생성한다. 아래의 예제는 하나의 Pod에서만 엑세스 가능하도록 accessMode를 ReadWriteOnce로 설정하였다.
apiVersion: v1
kind : PersistentVolumeClaim
metadata:
name: pv-claim-demo
spec:
storageClassName: ""
volumeName: pv-demo
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20G
4. Pod 생성 : Pod를 생성하여 PVC를 연결한다. pc-claim-demo를 볼륨에 연결한 후, 이 볼륨을 /data에 마운트 한 예제이다. 이후 df -k로 디스크 연결 상태를 확인해보면 된다.
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: terrypath
mountPath: /data
volumes:
- name : terrypath
persistentVolumeClaim:
claimName: pv-claim-demo
cf)
Dynamic Provisioning : 앞에서 처럼 PV를 수동으로 생성한후 PVC 바인딩을 한 후에 Pod에서 사용할 수도 있지만, k8s 1.6 버전부터 동적 생성 기능을 지원한다. 이는 시스템 관리지가 별도로 디스크를 생성하고 PV를 생성할 필요 없이 PVC만 정의하면 이에 맞는 물리디스크를 생성하고 PV 생성을 자동화 해준다. 사용방법은 아래와 같이 그냥 PVC에 필요한 디스크 용량을 지정해 놓으면 된다. 이후 Pod를 생성하여 사용하면 된다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mydisk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 30Gi
ref)
https://bcho.tistory.com/1259?category=731548
https://www.redhat.com/ko/topics/containers/what-is-kubernetes
'Kubenetes' 카테고리의 다른 글
| Kubenetes 정리#3(helm) (0) | 2022.09.29 |
|---|